

Resolving the Cambridge capital controversy with information theory
Resolving the Cambridge capital controversy with information theory
Apples × Oranges, not Apples + Oranges

I added something in a footnote on my post on inflation that I wanted to elaborate on regarding the “Cambridge capital controversy” (CCC) — an argument effectively between Cambridge, MA and Cambridge, UK about the definition of “capital”. I’ve constructed yet another snarky title in the series. The story so far:
Resolving the Cambridge capital controversy with abstract algebra
The larger point of this post was to prove that information equilibrium is a group under multiplication, but as it fails to be a ring under multiplication and addition it means you can’t just add things that are information equilibrium and get something else in the space of information equilibrium relationships. This essentially says Joan Robinson had a sense in which she was right. (However, in this latest installment I will show how it’s not hard to get around down below.) The link at the beginning of the post was to a YouTube video of Prince’s “Controversy” which has since been deleted.
Resolving the Cambridge capital controversy with MaxEnt
Samuelson later conceded that Sraffa and Robinson were correct about the CCC — so-called reswitching arguments made capital (aggregate production functions) a non-sensical construction since you could create individual firm production functions that varied with the interest rate in a discontinuous way that could not be aggregated. In the blog post, I use the partition function approach (maximum entropy) to an ensemble of information equilibrium relationships to show you can get emergent smooth aggregate production function even if the underlying ones for individual firms are not C² functions. While Sraffa’s examples could exist, they represent a tiny pathological piece of the state space that would require extreme coordination among many firms or a very limited number of firms to realize. This construction is more like a real analysis proof that they don’t always exist, but under realistic assumptions about the economy (i.e. a large number of firms that aren’t perfectly coordinated), the resulting aggregate production function is always approximately smooth. (I also added a bit where I laid out my opinion that Anwar Shaikh’s “humbug” paper misrepresents its claims in ways that at least borders on academic fraud. Solow was nicer, but I do not suffer that kind of BS.)
Resolving the Cambridge capital controversy with logic
While the first blog post predated my Twitter presence (at least in terms of econ), the second was deep into it — and therefore generated a bunch of illogical “rebuttals” that I replied to in this post. “Look at this paper that uses N = 2 firms!” Well, yes but my counterpoint is for N >> 1 firms. “Look at this paper that requires C² functions!” Well, yes, but my counterpoint doesn’t require C² functions (which was the original re-switching argument btw). “If we only look at data that is consistent with Cobb Douglas production functions then any data is consistent with Cobb Douglas productions functions!” Ok, you win on that one.
So what now?
As I said in that footnote, Apples + Oranges doesn’t make sense but Apples × Oranges does. You are not adding up drill presses and printing presses to create “capital” in the information theory approach, but rather producing a direct product of the opportunity set for each capital component to create a multi-dimensional state space constrained by a capital budget hyperplane (this is 3D with a 2D budget hyperplane):
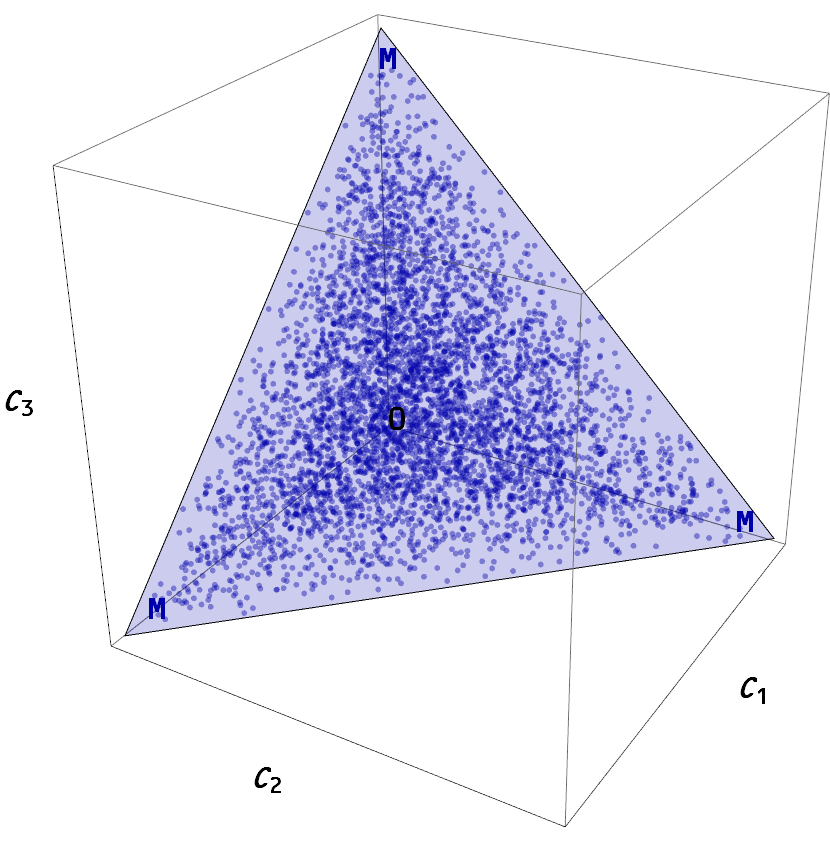
The information entropy you compute is over this entire state space, and while you can’t add up the drill presses and the printing presses you can add up the information entropy of drill press state probabilities and printing press state probabilities because they’re both measured in bits. What this does is affect the information transfer index k that measures the relative information content of “events” in this multi-dimensional capital supply space (consisting of capital “supply events”, such as turning on two drill presses and one printing press) and the multi-dimensional output demand space (consisting of “output events”, such as a printed block of wood with two holes for mounting). This combination creates a “transaction event” — or in this production function context a “GDP event”.
Years ago, I referred to information equilibrium as the Dungeons & Dragons approach to economics. Using this analogy, these supply events would be combinations of rolling several different kinds of dice — say 6-sided for the drill press events and 20-sided for the printing press events. Each die represents a different state space and to fully describe this example, you need multiple dimensions but in the end each roll reveals 33 bits of information (one 20-sided die and 11 6-sided dice).

Information equilibrium is about matching up the rolls on the supply side and the demand side — or at least the information entropy such that in the limit of a large number of rolls (transaction events) the realized distribution (post-roll) is approximately equal to the distribution the events are drawn from (pre-roll).
Now you could say “oh, this is just the approach of assigning prices to the capital goods and adding those up”. And in some abstract sense, yes, it is kind of similar. However, the Solow model and the aggregate production function under discussion in the CCC is about real quantities. Therefore, if you use prices you end up having to take them back out — which makes this difficult to then compare two different times which unfortunately is exactly what you are trying to do with a growth model1.
The closer analogy is that the information theory approach is similar to assigning utility to capital goods, as it creates a formally similar differential equation2. However, focusing on this analogy doesn't really capture the fact that the primary answer information equilibrium gives is basically “yes, an aggregate production function is an approximation and will change over time due to the changing capital state space”. That's because even if we add up all the capital goods into a single state space K, there are still a huge number of different outputs (nothing produces "GDP") so the Solow model is only
for capital K and labor L to leading order when ⟨α⟩ and ⟨β⟩ vary slowly enough. They should vary relatively slowly — as additional states are added to the state space the number of available αᵢ states increase but maximum entropy means it is more and more likely that lower αᵢ states are occupied3. This results in a pretty slowly varying function vs log L or log K:
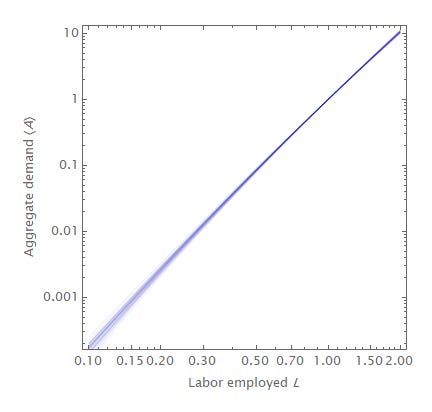
The slope of those lines are ⟨β⟩ (i.e. log ⟨A⟩ ~ ⟨β⟩ log L) for a particular throw of an economy with a random distribution of βᵢ states (it is similar for K and ⟨α⟩).
Since we take ⟨α⟩ and ⟨β⟩ to be empirically measured, the end result of all of this partition function / maximum entropy / information equilibrium formalism is basically the same result Solow and Samuelson came to — it works empirically to some degree in the same way g = 9.8 m/s² works to some degree. It is an empirical question to find the limitations, the scope conditions, as the theory already tells us it should fail over a long enough period of growth. Points to both Cambridge MA (it “works” empirically) and Cambridge UK (it should fall apart at some point) for simultaneously being kind of on the right track.
In that sense, the Cambridge capital controversy is something of a distraction that sees economics as a branch of philosophy or logic rather than a branch of science. Some physicists come along and say “given our assumptions, logically an electron in a hydrogen atom should radiate all its energy away and anything with a temperature should irradiate you with UV light” and Nature says “hah” and continues along with stable hydrogen atoms and hot things glowing red. It is up to the scientists to adapt their thinking to the real world, not the other way around. The Solow model apparently “working” — even according to people (e.g. Jonathan Temple [see here]) who are convinced aggregate production functions are not a thing — should make economists question their reasoning that allows them to come to a conclusion contrary to empirical evidence.
However, I do think it is useful to address an old “controversy” like this using a new paradigm like information equilibrium. It serves a dual purpose of showing how the new paradigm fits in with the existing approaches as well as showing how useful it can be in addressing previously sticky problems. It would be useless if it just produced the same results of other frameworks, and it would never catch on if it made no connection to the work that has gone before.
Back in my original post on abstract algebra, I added a footnote where I show the purportedly sensible information equilibrium relationship you can generate this way has an information transfer index that becomes dependent on prices in a non-trivial way.
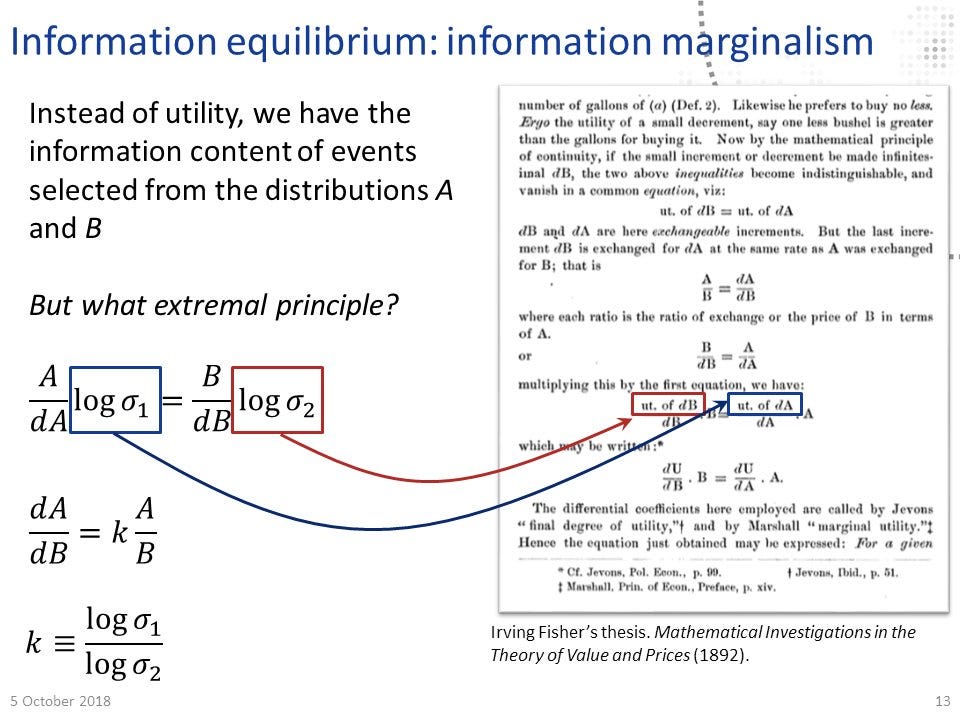
In Irving Fisher’s 1892 thesis, he wrote down a very similar differential equation to information equilibrium but in terms of utility:
It is more and more likely that a given unit of capital is being used in a low productivity sector because there are more ways to produce and economy with a given rate of growth out of many low growth states than a few high growth states.