


How good is the price level function approximation?

In this post I defined the partition function approach and noted that the "ansatz" (i.e. fancy guess)
$$
\text{(1) } P = p_{0} \frac{1}{\kappa (NGDP, M0)} \left( \frac{M0}{m_{0}}\right)^{1/\kappa (NGDP, M0) - 1}
$$
seemed to be a pretty good approximation to
$$
\text{(2) } P = p_{0} \langle a (m/m_{0})^{a - 1} \rangle
$$
which I intend to explore further in this post. First, I needed to see how the expected valueof $NGDP \sim \langle m^{a} \rangle$ (in 100 random markets again) worked against the empirical data. In the following plot I show the equation (black) along side the data (blue) in both log scale and linear scales:


This was a two parameter fit: and overall normalization of $NGDP$ and the relative normalization of $m$ so that
$$ NGDP = n_{0} \langle (m/m_{0})^{a} \rangle $$
This fit was then used in the price level ansatz equation (1) and compared with the numerical evaluation of the expectation value equation (2). What I am doing here is trying to figure out how well the functional form (1) approximates the "true" solution (2). It turns out it fits pretty well:
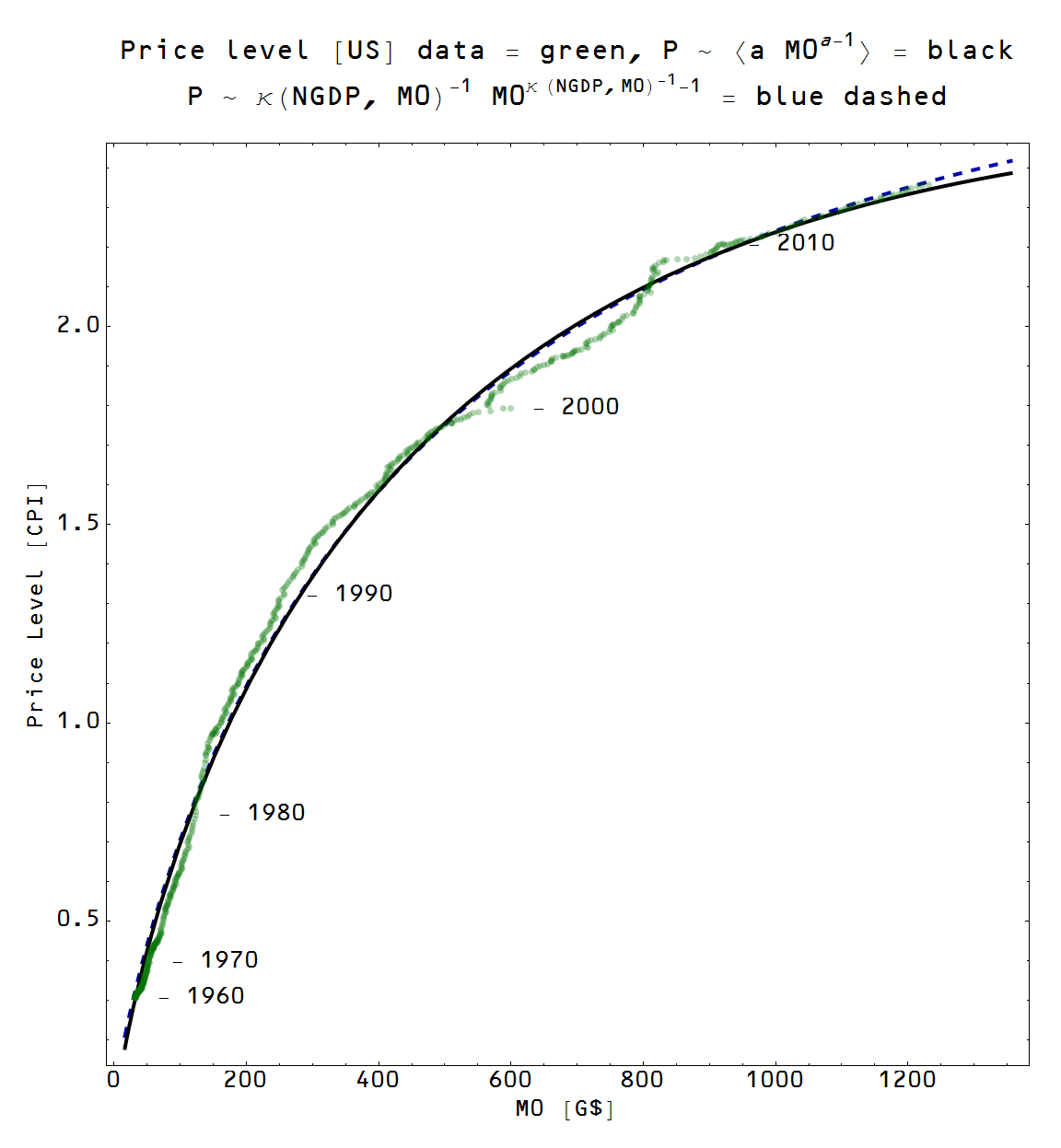

The ansatz (blue dashed), which was motivated through some squishy arguments [1], is a pretty good approximation to the exact solution (black), both of which fit pretty well to the data (green), again shown in log and linear scales. This means that the approach to macroeconomics taken on this blog has some pretty solid grounding.
[1] Equation (1) uses the definition of the information transfer index as counting the number of symbols and posits that the number of symbols in the demand is proportional to NGDP, while the number of symbols in the supply is proportional to the money supply. Additionally, there is an assumption that changes in the information transfer index are slow (compared to changes in the size of the economy or the money supply) so it can be taken out the integral.